在Python中,列表是一种常用的数据结构,它可以存储多个不同类型的数据,比如数字,字符串,布尔值等。列表的元素可以通过索引来访问和修改,列表也可以进行切片,拼接,排序等操作。列表是一种可变的序列,也就是说,我们可以随时向列表中添加或删除元素,或者改变列表中元素的值。
但是,有时候我们需要对列表中的元素进行一些数学运算,比如求和,平均,最大,最小等。这时候,如果列表中的元素是字符串类型,就会出现问题,因为字符串类型不能直接参与数学运算。例如,如果我们有一个列表lst = [‘1’, ‘2’, ‘3’],我们想要求它的和,就会报错:
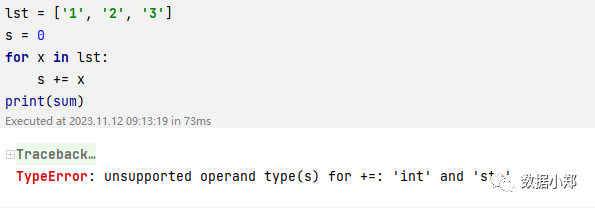
这是因为x是一个字符串,而sum是一个整数,它们不能用+=运算符相加。为了解决这个问题,我们需要把列表中的字符串转换为数字,这个过程就叫做【字符数值化】。
字符数值化的目的是为了让列表中的元素能够参与数学运算,同时也为了保留数据的含义和特征。字符数值化的方法有很多,比如使用内置函数,使用列表推导式等。
在本文中,我们将介绍这两种常用的字符数值化的方法,并且通过一个案例来展示它们的应用。
问题引入
假设我们有一个关于学生考试成绩的数据集,它包含了学生的姓名,语文,数学,英语三门科目的成绩,如下表所示:
我们可以用一个列表来存储这个数据集,每个元素是一个子列表,表示一行的数据,如下所示:
data = [['张三', '85', '90', '80'],['李四', '80', '95', '85'],['王五', '75', '85', '90'],['赵六', '90', '80', '75']]
我们可以看到,这个列表中有两种类型的数据,一种是字符串,表示学生的姓名,另一种是字符串,表示学生的成绩。如果我们想要对这个数据集进行分析,比如求每个学生的总分,平均分,最高分,最低分等,我们就需要将成绩这一列的字符串转换为数字。我们可以使用以下三种方法来实现这个目的。
方法一内置函数
Python提供了一些内置函数,可以将字符串转换为数字,比如int()函数,float()函数,eval()函数等。这些函数的用法很简单,只需要将字符串作为参数传入,就可以返回相应的数字。例如,如果我们有一个字符串’123’,我们可以用int()函数将它转换为整数:
s = '123'n = int(s)print(n)print(type(n))
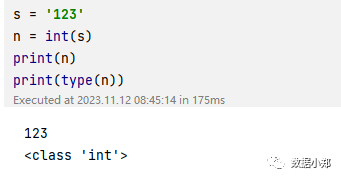
我们可以看到,n的值是123,类型是int,表示整数。
类似地,我们可以用float()函数将字符串转换为浮点数,用eval()函数将字符串转换为相应的数值类型。
对于eval函数相关语法、案例介绍:
例如,如果我们有一个字符串’3.14’,我们可以用float()函数或者eval()函数将它转换为浮点数:
s = '3.14'n1 = float(s)n2 = eval(s)print(n1)print(type(n1))print(n2)print(type(n2))
我们可以看到,n1和n2的值都是3.14,类型都是float,表示浮点数。
使用内置函数的优点是简单直接,缺点是需要知道字符串的具体类型,才能选择合适的函数。如果字符串的类型不确定,或者不是一个合法的数字表示,就会报错。
例如,如果我们有一个字符串abc,我们无法用任何内置函数将它转换为数字:
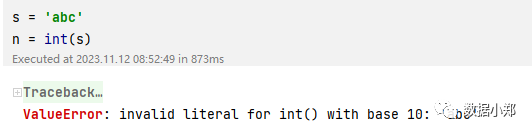
为了避免这种错误,我们可以使用try…except语句来捕获异常。并进行相应的处理。
例如,我们可以定义一个函数,尝试用eval()函数将字符串转换为数字,如果失败,就返回原字符串:
def str_to_num(s):try:return eval(s)except:return s
这样,我们就可以用这个函数来处理任意类型的字符串,不用担心报错。例如,如果我们有一个字符串abc,我们可以用这个函数将它转换为数字,如果失败,就返回原字符串:
s = 'abc'n = str_to_num(s)print(n)print(type(n))
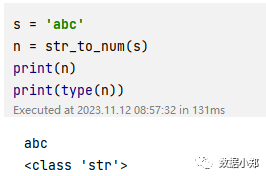
我们可以看到,n的值是abc,类型是str,表示字符串。
使用这个函数,我们可以对列表中的每个元素进行转换,只需要用一个循环遍历列表,然后用str_to_num()函数处理每个元素,就可以得到一个新的列表,其中的字符串都被转换为数字。
例如,如果我们有一个列表lst = [‘1’, ‘2’, ‘3’],我们可以用这个函数将它转换为数字:
lst = ['1', '2', '3']new_lst = []for x in lst:new_lst.append(str_to_num(x))print(new_lst)
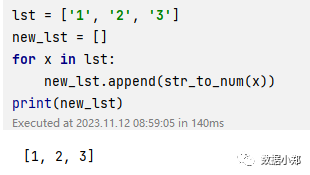
我们可以看到,new_lst的值是[1, 2, 3],类型是list,表示列表,其中的元素都是数字。
使用这种方法,我们可以对数据集中的成绩进行转换,只需要用一个双重循环遍历数据集,然后用str_to_num()函数处理每个成绩,就可以得到一个新的数据集,其中的成绩都被转换为数字。
data = [['张三', '85', '90', '80'],['李四', '80', '95', '85'],['王五', '75', '85', '90'],['赵六', '90', '80', '75']]new_data = []for row in data:new_row = []for x in row:new_row.append(str_to_num(x))new_data.append(new_row)print(new_data)
我们可以看到,new_data的值是`[[‘张三’, 85, 90, 80], [‘李四’, 80, 95, 85], [‘王五’, 75, 85, 90], [‘赵六’, 90, 80, 75]]`,类型是list,表示列表,其中的成绩都是数字。
使用这种方法,我们就可以对数据集中的成绩进行数学运算,比如求每个学生的总分,平均分,最高分,最低分等。
例如,如果我们想要求每个学生的总分,我们可以用一个循环遍历数据集,然后用sum()函数求和每个子列表中的成绩,就可以得到一个新的列表,其中的元素是每个学生的总分。例如,如果我们有一个数据集new_data,我们可以用这个函数求每个学生的总分:
new_data = [['张三', 85, 90, 80],['李四', 80, 95, 85],['王五', 75, 85, 90],['赵六', 90, 80, 75]]total_score = []for row in new_data:total_score.append(sum(row[1:]))print(total_score)
我们可以看到,total_score的值是[255, 260, 250, 245],类型是list,表示列表,其中的元素是每个学生的总分。
类似地,我们可以用其他的函数或表达式来求每个学生的平均分,最高分,最低分等。例如,如果我们想要求每个学生的平均分,我们可以用一个循环遍历数据集,然后用sum()函数和len()函数求平均每个子列表中的成绩,就可以得到一个新的列表,其中的元素是每个学生的平均分。例如,如果我们有一个数据集new_data,我们可以用这个函数求每个学生的平均分:

我们可以看到,average_score的值是[85.0, 86.66666666666667, 83.33333333333333, 81.66666666666667],类型是list,表示列表,其中的元素是每个学生的平均分。
方法二使用列表推导式
列表推导式是一种简洁的创建列表的方式,它可以对列表中的每个元素进行操作或筛选。列表推导式的语法是:
[expression for item in iterable if condition]其中,expression是一个表达式,用于对item进行操作;item是一个变量,用于遍历iterable;iterable是一个可迭代的对象,比如列表,元组,字符串等;condition是一个可选的条件,用于筛选item。
使用列表推导式的优点是简洁高效,缺点是可读性较差,不适合复杂的逻辑。
使用列表推导式,我们可以对列表中的每个元素进行转换,只需要用一个表达式将每个元素转换为数字,就可以得到一个新的列表,其中的元素都是数字。例如,如果我们有一个列表lst = [‘1’, ‘2’, ‘3’],我们可以用列表推导式将它转换为数字:
lst = ['1', '2', '3']lst = [int(x) for x in lst]print(lst)
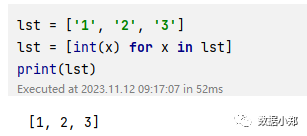
我们可以看到,lst的值是[1, 2, 3],类型是list,表示列表,其中的元素都是数字。
使用这种方法,我们可以对数据集中的成绩进行转换,只需要用一个列表推导式将每个子列表中的成绩转换为数字,就可以得到一个新的数据集,其中的成绩都是数字。例如,如果我们有一个数据集data,我们可以用列表推导式将它转换为数字:
data = [['张三', '85', '90', '80'],['李四', '80', '95', '85'],['王五', '75', '85', '90'],['赵六', '90', '80', '75']]data = [[row[0]] + [int(x) for x in row[1:]] for row in data]print(data)

我们可以看到,data的值是[[‘张三’, 85, 90, 80], [‘李四’, 80, 95, 85], [‘王五’, 75, 85, 90], [‘赵六’, 90, 80, 75]],类型是list,表示列表,其中的成绩都是数字。
使用这种方法,我们也可以对数据集中的成绩进行数学运算,比如求每个学生的总分,平均分,最高分,最低分等。例如,如果我们想要求每个学生的总分,我们可以用一个列表推导式求和每个子列表中的成绩,就可以得到一个新的列表,其中的元素是每个学生的总分。例如,如果我们有一个数据集data,我们可以用列表推导式求每个学生的总分:
data = [['张三', 85, 90, 80],['李四', 80, 95, 85],['王五', 75, 85, 90],['赵六', 90, 80, 75]]total_score = [sum(row[1:]) for row in data]print(total_score)
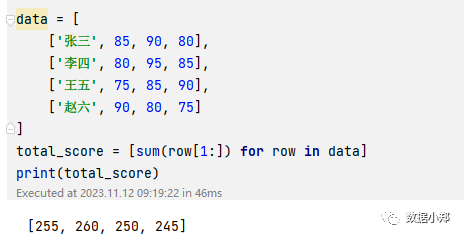
我们可以看到,total_score的值是[255, 260, 250, 245],类型是list,表示列表,其中的元素是每个学生的总分。
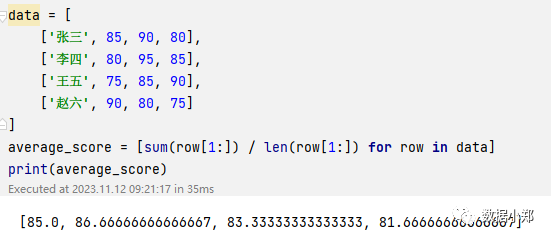
类似地,我们可以用其他的函数或表达式来求每个学生的平均分,最高分,最低分等。例如,如果我们想要求每个学生的平均分,我们可以用一个列表推导式求平均每个子列表中的成绩,就可以得到一个新的列表,其中的元素是每个学生的平均分。例如,如果我们有一个数据集data,我们可以用列表推导式求每个学生的平均分:
data = [['张三', 85, 90, 80],['李四', 80, 95, 85],['王五', 75, 85, 90],['赵六', 90, 80, 75]]average_score = [sum(row[1:]) / len(row[1:]) for row in data]print(average_score)
限时特惠:本站每日持续更新海量各大内部网赚创业教程,会员可以下载全站资源点击查看详情
站长微信:11082411
