需求描述:朋友在平时工作中会经常重复性地打开不同PDF文件,选取其中特定的几组信息复制粘贴到不同的Word文档中,完成一份PDF文件平均耗时15分钟,想试试Python代码能否帮忙。


由于其涉及文件隐私,将需求简化如下:我这提供一份PDF版《笨办法学Python》,想把其中第五页的第1段和第4段填充到Word文档 “笔记.docx” 特定位置:
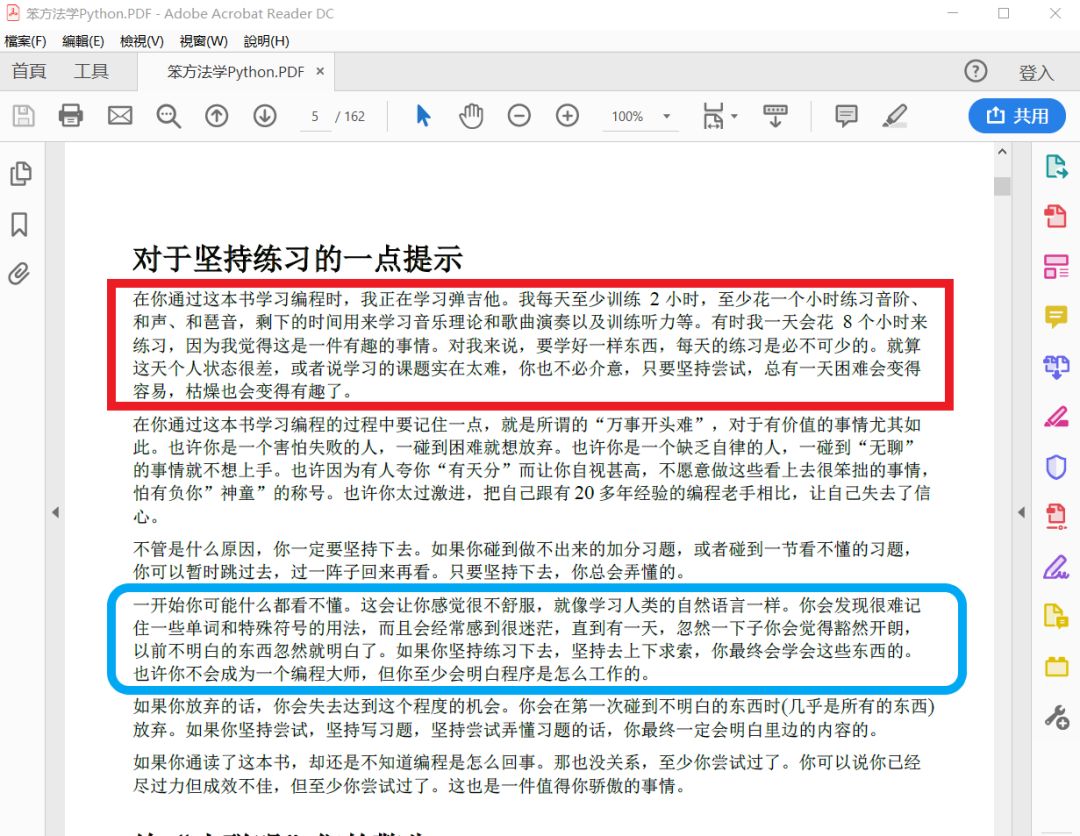
上图为PDF中的目标文字;下图为Word文档要填充的位置:
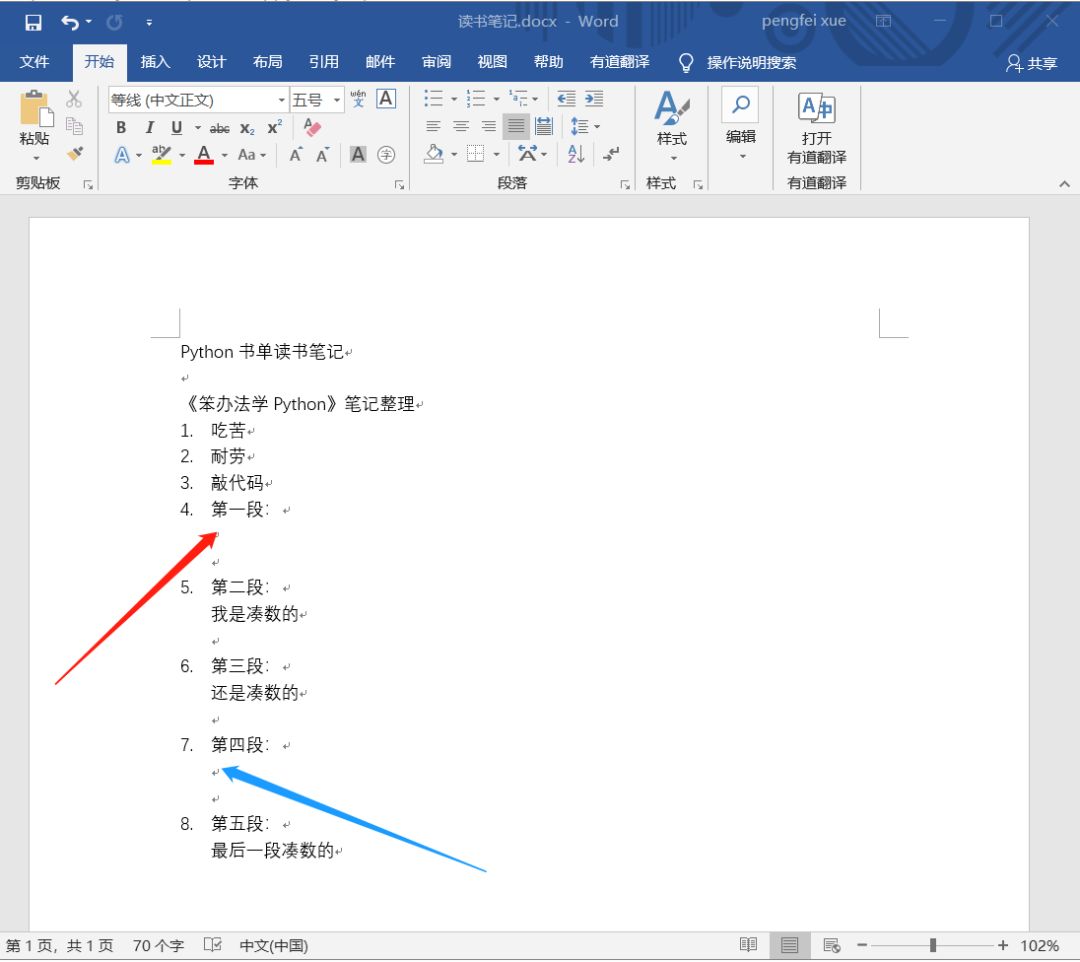
思路
首先利用PDFMiner模块解析PDF文件,转化成PDF内容的文本列表;根据目标位置在列表中提取目标文本;利用Python处理Word文档的库docx-mailmerge模块,进行文本填充。
PDFMiner模块
PDFMiner是一个专注于从PDF文档中提取、分析文本信息的工具。它不仅可以获取特定页码特定位置处的信息,也能获得字体等信息。其工作原理如图所示:
看不懂原理图没关系,我们关心的是应用问题。首先安装PDFMiner,注意Python3要安装pdfminer3k,可以通过pip install pdfminer3k进行安装
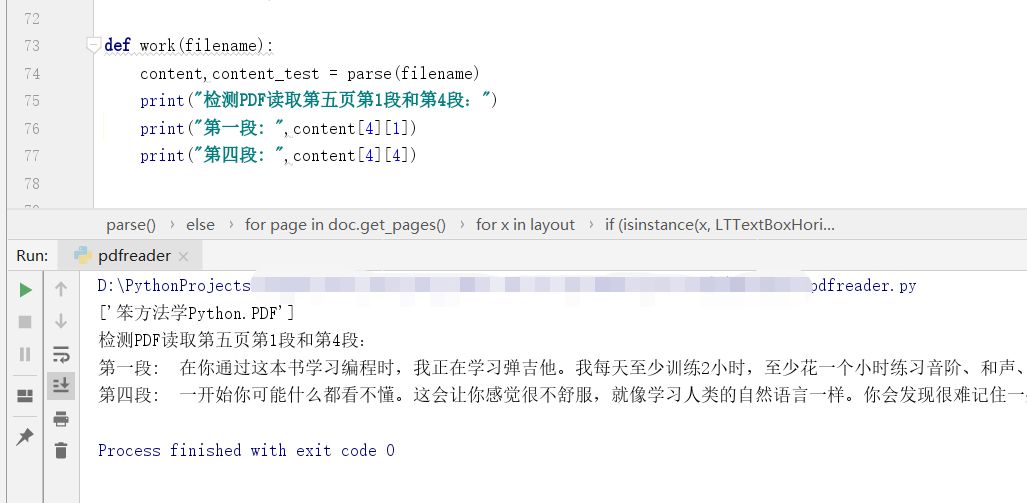
解析PDF涉及代码步骤较多,先不展开,文末提供注释源码供参考。通过PDFMiner解析,文本内容按区域存到不同页码的文本list中;每一页又作为元素存入整个文档的list中。即假设content代表整个PDF文本信息,content[0]为第一页信息,content[4]即我们想要的第五页信息。而第五页中,按照list元素顺序,我们想要的第一段和第四段就可以通过content[4][1]和content[4][4]拿到了:
docx-mailmerge模块
这个模块的应用类似于你先在Word文档中特定位置去定义好变量,之后在代码中通过MailMerge函数为变量赋值。
首先是安装:pip install docx-mailmerge
接下来去Word文档中定义要插入的变量,在要插入文本的位置选择 “插入”→“文档部件”→“域”:
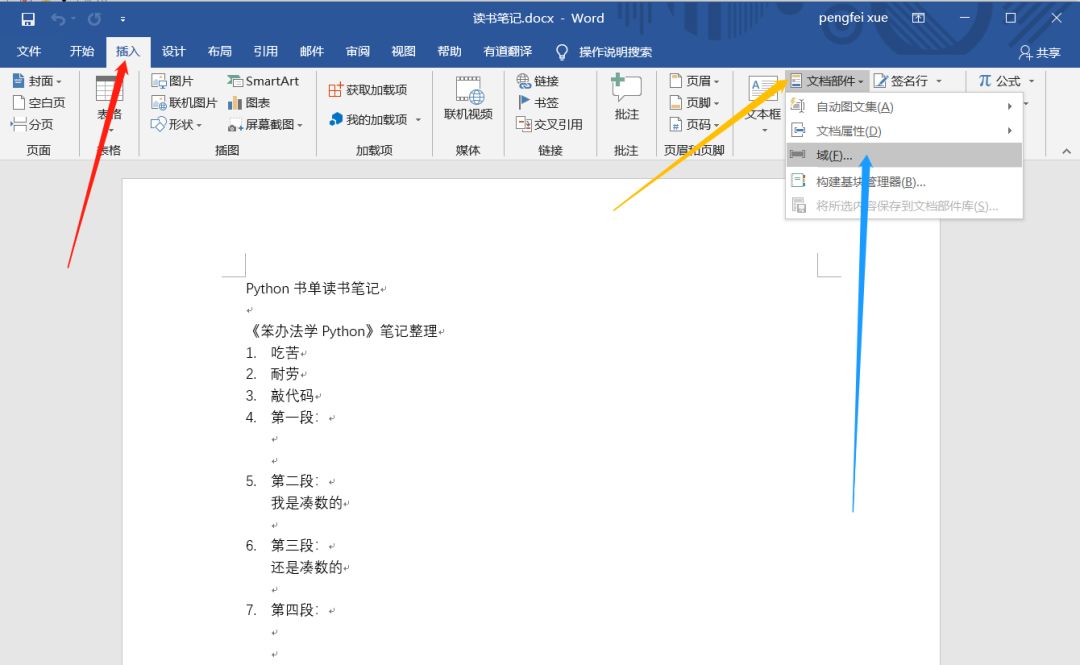
在弹出的窗口中选择mailmerge变量,中文直译“邮件合并”,域名是自己定义的变量名,这里我用firstTED 来代表第一段:
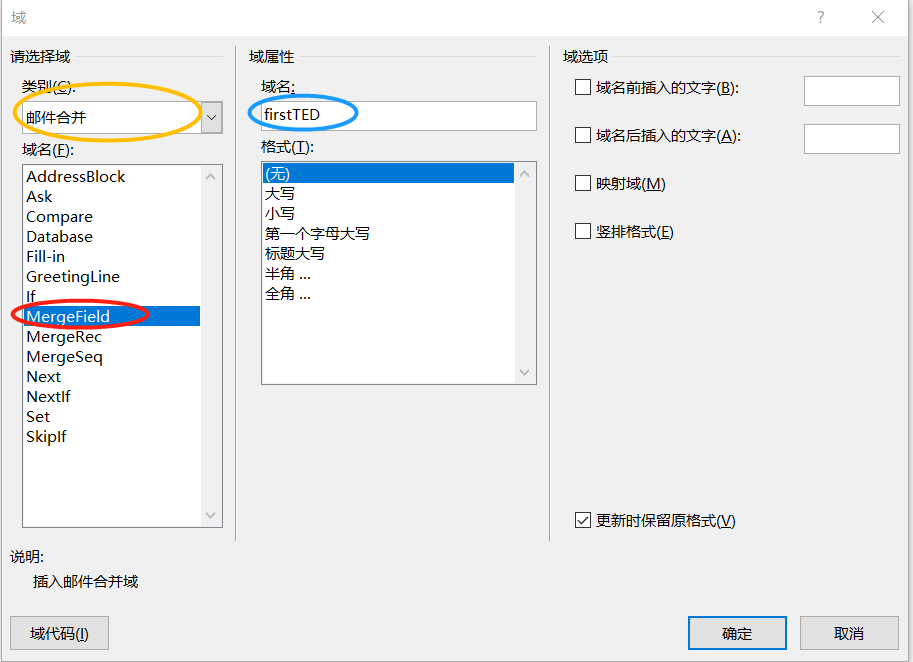
设置完成后会看到出现在Word文档中。同理,我们设置fourthTED来代表第四段,最终结果如图:

至此,Word文档中变量定义完成,继续回到代码中。我们已经拿到了第一段和第四段的文本,接下来就是将其和新定义的firstTED 和 fourthTED 融合:
template = "../读书笔记.docx"document = MailMerge(template)document.merge( firstTED = content[4][1], fourthTED = content[4][4],)document.write("读书笔记更新.docx")
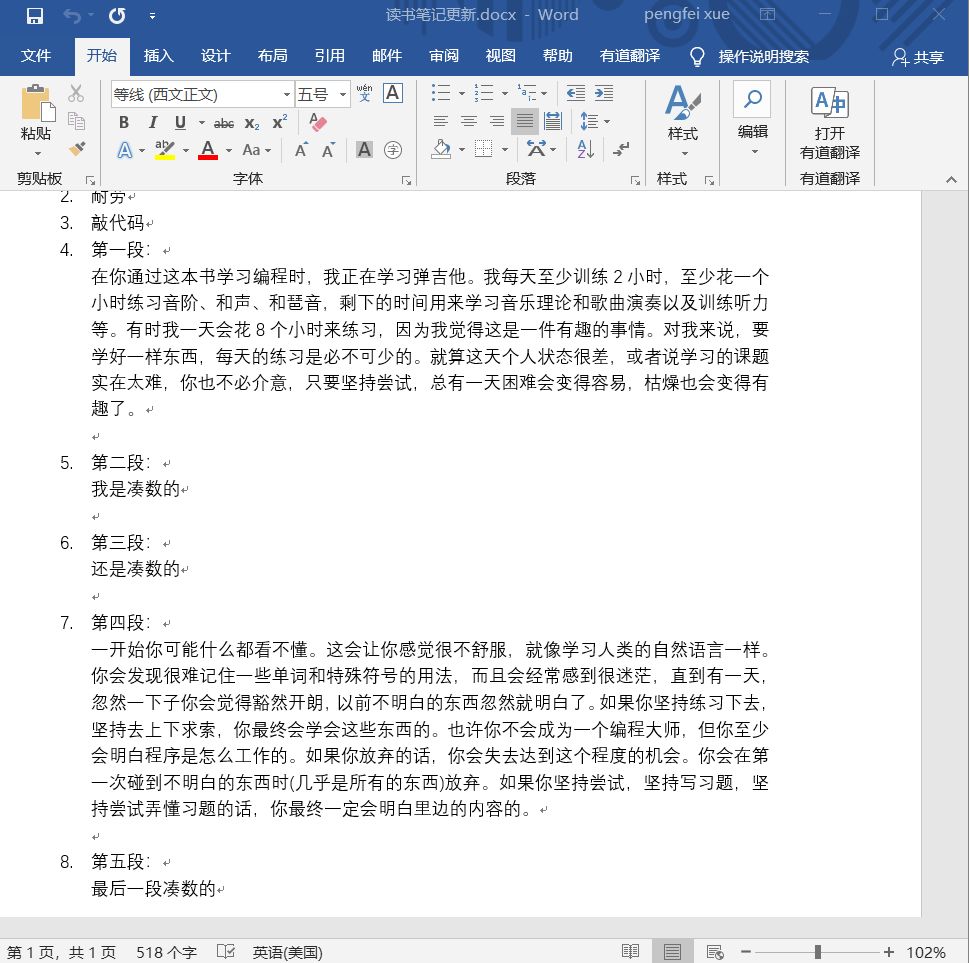
最终在PDF文件旁会生成新的“读书笔记更新.docx”:
其内容如图:
目标达成!写给朋友的初版代码,对于能拿到的文本信息准确度也是很高的,而且可以批量处理文档。代码运行几秒钟,便将人力几个小时的工作完成了,余下的是相对轻松的校验和修正。可能你一天的繁琐工作,对代码而言就是几秒的事情。
回顾
就实现效果来看,达到了预期,但仍有待提高。最终效果与PDF文件的格式是否规范有直接关系,有许多扫描件PDF文档每页都像是图片,就无法通过PDFMiner顺利获取到文本信息。后续我们将尝试先把PDF转图片,再通过OCR识别图片中文字信息的思路来搞定。
此外,为了展示,选用的PDF和Word文档以及要插入的信息都较规范简洁,在实际需求中,因为批量操作,也会遇到各种大小问题,这些都要在实战中去不断完善。
扫描下方海报二维码
限时特惠:本站每日持续更新海量各大内部网赚创业教程,会员可以下载全站资源点击查看详情
站长微信:11082411
